
Supply chains run on data. Every shipment scan, warehouse update, carrier ping, and inventory count generates it continuously. The real problem? Most of that data is locked inside separate systems with no fast, reliable way to bring it together. A data lake for supply chain logistics fixes this by pulling all that raw data into one place, accessible whenever teams need it for a decision.
According to a GEODIS Supply Chain Worldwide Survey, only 6% of companies report full end-to-end supply chain visibility. That stat alone tells you how fragmented most logistics data environments still are, even with modern tools in place.
A central data layer changes that picture. Instead of exporting spreadsheets and manually matching records across five platforms, teams query one source and get a current, accurate view of what is actually happening on the ground.
What is a Data Lake and How Does It Work in Logistics?
A data lake is a centralized storage system built to hold large volumes of raw data in its original format. It handles structured, semi-structured, and unstructured data without forcing everything into a fixed schema before storing it.
Logistics data is messy by nature. Freight invoices, IoT sensor feeds, EDI records, GPS coordinates, customs documents, and demand forecasts all look different from each other. A scalable data lake logistics setup takes all of these formats in without requiring upfront transformation, which is precisely what high-volume, fast-moving supply chains need.
This is also where the data lake vs data warehouse logistics conversation becomes practical. A data warehouse holds cleaned, pre-processed data for reports that were designed in advance. A data lake stores everything raw, giving data engineers the flexibility to run queries they did not plan for at setup. That adaptability directly supports real-time supply chain visibility data use cases.
Data Lake vs. Data Warehouse in Supply Chain Logistics : Quick Comparison
| System Feature | Data Lake Architecture | Data Warehouse Architecture |
|---|---|---|
| Format Acceptance | Raw, unstructured, semi-structured | Highly structured tables only |
| Schema Processing | Applied during reading (schema-on-read) | Applied before writing (schema-on-write) |
| Storage Cost | Low cost for massive file volumes | High cost for premium storage |
| Primary Use Case | Machine learning and predictive modeling | Historical business intelligence reporting |
Why Supply Chains Struggle Without Centralized Data
Most supply chain teams are not short on data. They are short on connected data. Procurement sees one version of reality, logistics sees another, and warehouse managers work from a third system entirely. When those systems do not share data in real time, gaps open up and decisions fall behind actual operations.
Big data in logistics means high-volume, high-velocity data flowing simultaneously from dozens of sources. A mid-size distributor might track thousands of shipments, watch carrier performance, handle returns, and monitor warehouse slot availability all at once. Without a central platform, teams are forced to stitch all of that together by hand.
According to the Anvyl State of Supply Chain Report 2025, brands rank supply chain visibility analytics and reporting as the number one opportunity for their business. Yet the challenges they struggle with most are still data inaccuracies, data silos, and inconsistent data quality. A data lake for supply chain logistics targets all three directly.
- Inventory decisions get made using stale, batch-updated numbers
- Shipment delays get noticed after they have already cost time and money
- Carrier and supplier records contradict each other because systems do not talk
- Freight reporting stays surface-level without access to historical data depth
Supply chain data management built around a data lake closes these gaps. Rather than waiting for overnight exports, teams work from a continuously refreshed data layer that reflects current operations.
What Does Real-Time Visibility Look Like?
Real-time supply chain visibility data means knowing exactly what is happening across operations right now, not in a report from two hours ago. A logistics director or IT manager opens a supply chain reporting dashboard and sees live inventory positions, shipment statuses, and carrier performance from one view.
A data lake for supply chain logistics makes this possible by connecting ingestion pipelines directly to dashboards, alerting tools, and machine learning models. As new data arrives, whether it is a warehouse scan, a GPS ping, or a customs clearance update, it flows into the lake and gets processed. The reporting layer reflects current state, not a scheduled snapshot.
In 2025, 57% of supply chain professionals cited insufficient visibility as the biggest operational challenge. That gap persists wherever data sits in siloed systems rather than a central logistics data analytics platform built to handle live feeds.
- Live shipment status pulled from carrier APIs, GPS trackers, and IoT sensors
- Demand signals flowing from point-of-sale data directly into warehouse planning
- Automated alerts for delays, inventory thresholds, or SLA breaches
- Freight analytics data lake queries running without moving data to another system first
Supply chain data integration at this level removes the guesswork. Logistics teams react faster, procurement makes sharper calls, and IT has a clear, auditable data flow to manage and monitor without chasing down records across platforms.
How AWS and Azure Support Logistics Data Lakes
Cloud platforms have made building a cloud data lake supply chain far more practical for enterprise logistics teams. AWS Azure data lake logistics setups are the two most widely deployed options in production environments today, and both have matured considerably for supply chain workloads.
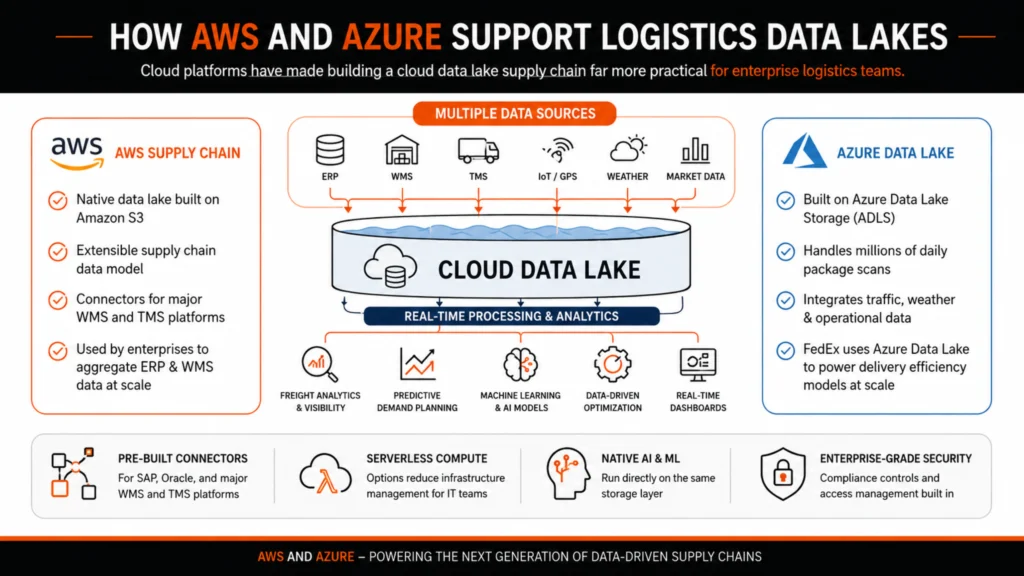
AWS Supply Chain includes a native data lake built on Amazon S3, designed to aggregate data from ERP and WMS systems using an extensible supply chain data model. It supports connectors for major warehouse and transportation management platforms, so teams are not rebuilding integrations from scratch.
FedEx uses Microsoft Azure Data Lake to process millions of daily package scans alongside traffic and weather data, feeding that combined dataset into delivery efficiency models. That is supply chain data integration at scale working in practice, with multiple raw data sources feeding one storage layer and real-time processing running on top of it.
Both platforms support freight analytics data lake querying, predictive demand planning, and data-driven supply chain optimization through built-in machine learning and analytics services.
- Pre-built connectors for SAP, Oracle, and major WMS and TMS platforms
- Serverless compute options reduce the infrastructure management load for IT teams
- Native AI and ML services run directly on the same storage layer
- Enterprise-grade security, compliance controls, and access management built in
Building a Scalable Data Lake for Logistics Operations
A scalable data lake logistics architecture does not need to start big. Most solid implementations begin with one high-value data source, such as shipment tracking or inventory feeds, and expand as the team builds confidence in the pipeline and data quality holds up under real use. Many organizations also rely on data lake consulting services to design scalable frameworks that align with long-term operational and analytics goals.
The architecture typically covers four layers: ingestion for both batch and streaming data, raw storage, a processing zone for cleansing and transformation, and a serving layer connected to dashboards, APIs, or machine learning pipelines. Supply chain data management at this level calls for close coordination between data engineers, IT architects, and logistics operations teams who actually use the output.
McKinsey’s Supply Chain Risk Pulse 2025 found that organizations pursuing digital transformation are best equipped to handle future disruptions. Building a solid data foundation sits at the center of that readiness.
PwC’s 2025 Digital Trends in Operations Survey reported that 96% of supply chain and operations leaders say digital tools have improved their visibility into end-to-end supply chain costs. A data lake for supply chain logistics is one of the primary infrastructure decisions behind that outcome.
- Streaming ingestion from IoT devices, carrier APIs, and EDI systems
- Data zones with raw, processed, and curated layers with clear ownership assigned
- Role-based access so logistics, finance, and IT teams each see what is relevant to them
- Monitoring and data lineage tracking to catch quality issues at the source, not downstream
Organizations that connect all their logistics data into a single platform gain the ability to run data-driven supply chain optimization at real scale, not just in periodic reports, but in live operational decisions made throughout the day.
If your team is currently dealing with fragmented visibility, slow reporting cycles, or data that does not match across your carrier and warehouse systems, a data lake architecture built for supply chain logistics is a concrete step worth putting on the roadmap.
FAQs
What is a data lake for supply chain logistics?
A data lake for supply chain logistics is a centralized storage system that collects raw data from ERP, WMS, TMS, IoT, and carrier systems in one place. Teams use it for real-time analytics, machine learning, and operational reporting.
How is a data lake different from a data warehouse in logistics?
A data lake stores raw, unformatted data from any source. A data warehouse holds pre-processed, structured data for fixed queries. Data lakes handle the volume and variety of logistics data without requiring a defined schema upfront.
Which cloud platforms are used for logistics data lakes?
AWS and Azure are the most widely used platforms. AWS Supply Chain includes a native data lake on Amazon S3, and Azure Data Lake Storage powers freight analytics and real-time visibility use cases including FedEx’s delivery operations.
How does a data lake support real-time supply chain visibility?
By ingesting data from all supply chain systems as it arrives and processing it in near real time, a data lake feeds live dashboards and automated alerts instead of relying on scheduled batch exports.
Can mid-size logistics companies build a scalable data lake?
Yes. Cloud platforms on AWS or Azure let teams start with a single data source, such as shipment tracking, and scale the data lake incrementally without large upfront infrastructure costs.
